Vous souhaitez partager votre contenu sur R-bloggers ? cliquez ici si vous avez un blog, ou ici si vous n’en avez pas.
CRAN, GitHub
TL;DR: {bdlnm} apporte les modèles bayésiens non linéaires à décalage distribué (B-DLNM) à R à l’aide d’INLA, permettant de modéliser des DLNM complexes, de quantifier l’incertitude et de produire des visualisations riches.
Arrière-plan
Le changement climatique accroît l’exposition à des conditions environnementales extrêmes telles que les vagues de chaleur et la pollution atmosphérique. Cependant, ces expositions ont rarement des effets immédiats. Par exemple:
-
- Une vague de chaleur aujourd’hui pourrait augmenter la mortalité quelques jours plus tard
- La pollution atmosphérique peut avoir des impacts cumulatifs et différés
Les modèles non linéaires à décalage distribué (DLNM) constituent le cadre standard pour étudier ces effets. Ils modélisent simultanément :
-
- Comment le risque change avec le niveau d’exposition (exposition-réponse)
- Comment le risque évolue dans le temps (lag-response)
Habituellement, en présence d’effets non linéaires, des splines sont utilisées pour définir ces deux relations. Ces deux bases sont ensuite combinées via une fonction de base croisée.
À mesure que les ensembles de données deviennent plus volumineux et plus complexes (par exemple, des études portant sur différentes régions et sur des périodes plus longues), les approches classiques montrent leurs limites. Les DLNM bayésiens étendent ce cadre en :
-
- Prise en charge de structures de modèles plus flexibles
- Fournir des distributions postérieures complètes
- Permettre une quantification plus riche de l’incertitude
Le nouveau package {bdlnm} étend le cadre du package {dlnm} à un paramètre bayésien, en utilisant Integrated Nested L’approximation de Laplace (INLA), une alternative rapide au MCMC pour l’inférence bayésienne.
Installation et chargement du package
Depuis mars 2026, le package est disponible sur CRAN :
install.packages("bdlnm")
library(bdlnm)
Au moins la version stable d’INLA 23.4.24 (ou la plus récente) doit être installée au préalable. Vous pouvez installer la dernière version stable d’INLA en :
install.packages(
"INLA",
repos = c(
getOption("repos"),
INLA = "
),
dep = TRUE
)
Maintenant, chargeons toutes les bibliothèques dont nous aurons besoin pour ce court tutoriel :
Charger les bibliothèques requises
# DLNMs and splines library(dlnm) library(splines) # Data manipulation library(dplyr) library(reshape2) library(stringr) library(lubridate) # Visualization library(ggplot2) library(gganimate) library(ggnewscale) library(patchwork) library(scales) library(plotly) # Tables library(gt) # Execution time library(tictoc)
Exemple pratique
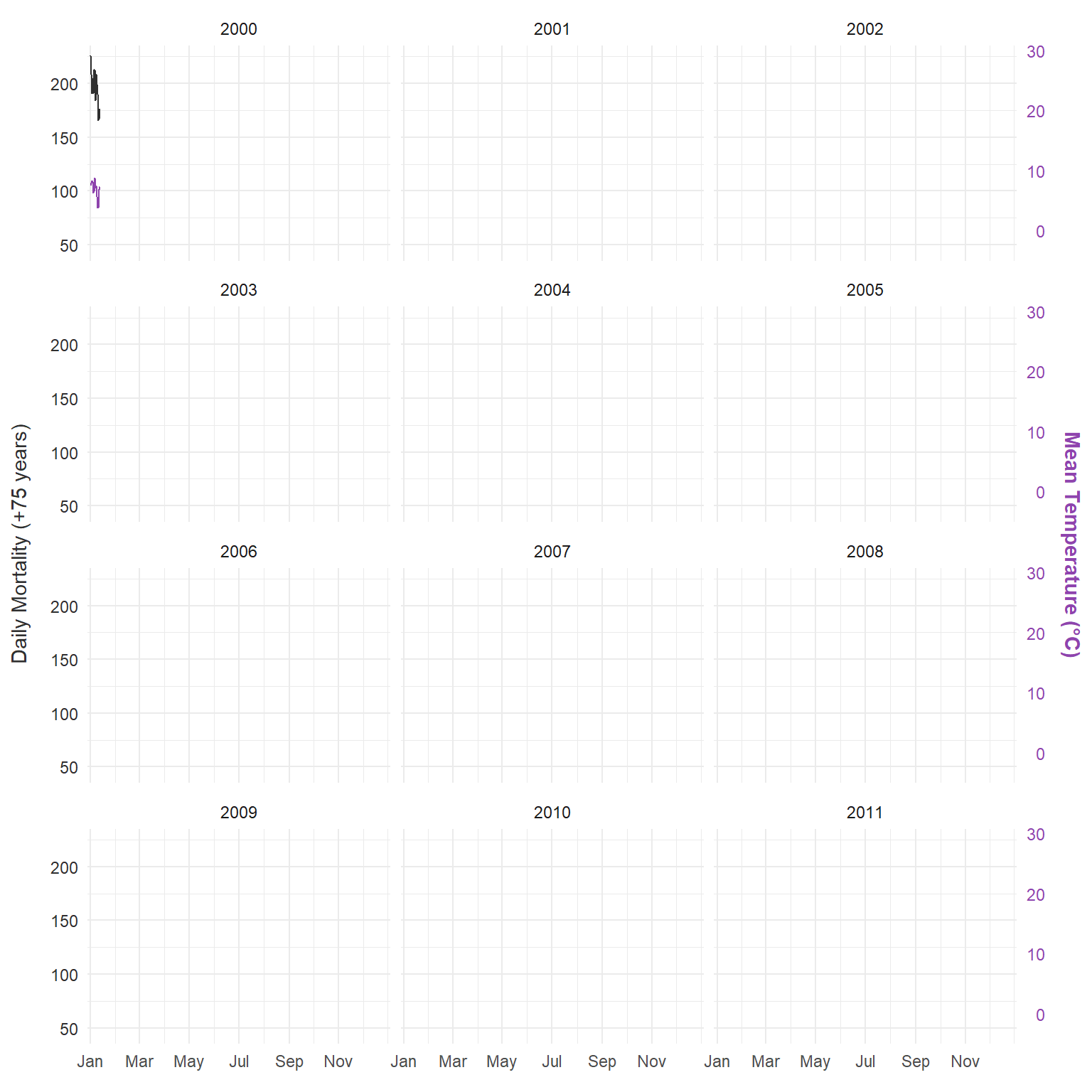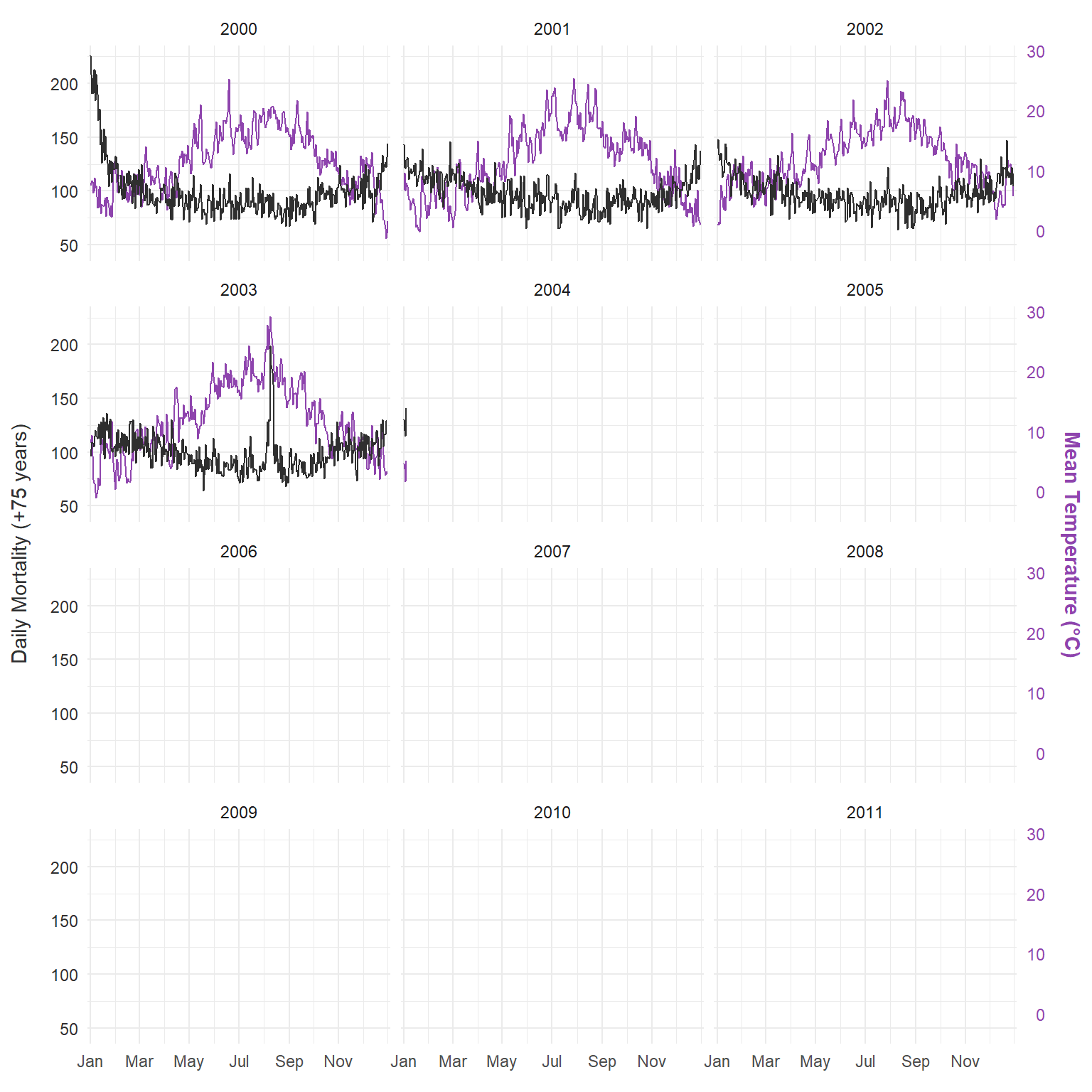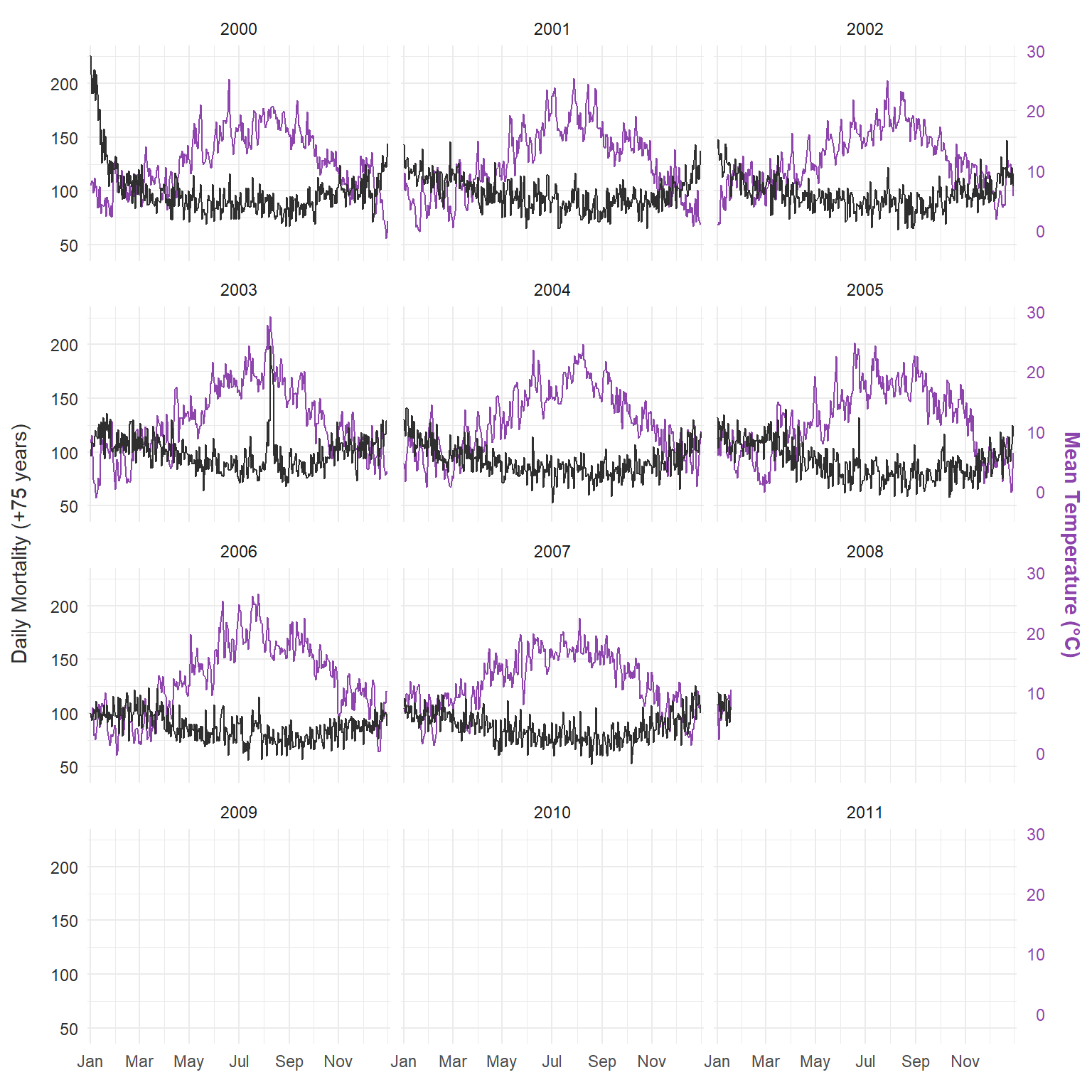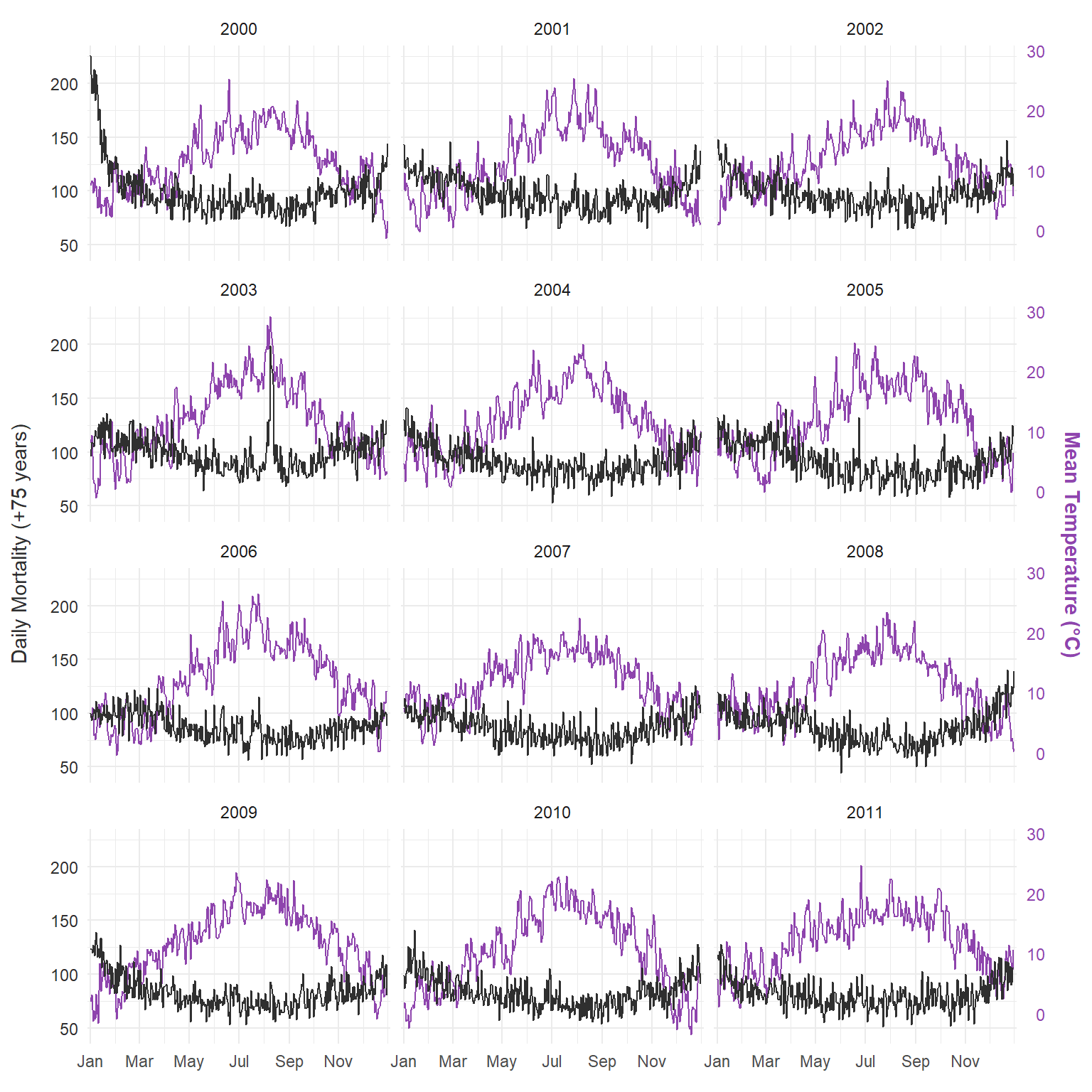
Nous utilisons l’ensemble de données intégré de Londres avec la température et la mortalité quotidiennes (75 ans et plus) de 2000 à 2012.
Avant d’ajuster un modèle, il est utile d’explorer les données brutes. Ce graphique montre la température moyenne quotidienne et la mortalité pour la tranche d’âge de 75 ans et plus à Londres de 2000 à 2012, offrant un premier aperçu de la série chronologique que nous essayons de modéliser :
col_mort <- "#2f2f2f"
col_temp <- "#8e44ad"
# Scaling parameters
a <- (max(london$mort_75plus) - min(london$mort_75plus)) /
(max(london$tmean) - min(london$tmean))
b <- min(london$mort_75plus) - min(london$tmean) * a
p <- ggplot(london, aes(x = yday(date))) +
geom_line(
aes(y = a * tmean + b, color = "Mean Temperature"),
linewidth = 0.4
) +
geom_line(
aes(y = mort_75plus, color = "Daily Mortality (+75 years)"),
linewidth = 0.4
) +
facet_wrap(~year, ncol = 3) +
scale_y_continuous(
name = "Daily Mortality (+75 years)",
breaks = seq(0, 225, by = 50),
sec.axis = sec_axis(
name = "Mean Temperature (°C)",
transform = ~ (. - b) / a,
breaks = seq(-10, 30, by = 10)
)
) +
scale_x_continuous(
breaks = yday(as.Date(paste0(
"2000-",
c("01", "03", "05", "07", "09", "11"),
"-01"
))),
labels = c("Jan", "Mar", "May", "Jul", "Sep", "Nov"),
expand = c(0.01, 0)
) +
scale_color_manual(
values = c(
"Daily Mortality (+75 years)" = col_mort,
"Mean Temperature" = col_temp
)
) +
labs(x = NULL, color = NULL) +
guides(color = "none") +
theme_minimal() +
theme(
axis.title.y.left = element_text(
color = col_mort,
face = "bold",
margin = margin(r = 8)
),
axis.title.y.right = element_text(
color = col_temp,
face = "bold",
margin = margin(l = 8)
),
axis.text.y.left = element_text(color = col_mort),
axis.text.y.right = element_text(color = col_temp)
) +
transition_reveal(as.numeric(date))
animate(p, nframes = 300, fps = 10, end_pause = 100)
Aperçu du modèle
Conceptuellement, le modèle DLNM :
-
-
Exposition-réponse : comment le risque évolue en fonction du niveau d’exposition
-
Réponse décalée : comment le risque évolue-t-il au fil du temps
-
Un modèle typique est :
où:
-
- un est l’interception
- CB(·) est la fonction de base croisée, définissant à la fois les relations exposition-réponse et retard-réponse
- b sont les coefficients associés aux termes de base croisée
- toikt sont des covariables variables dans le temps avec des coefficients correspondants ck
Spécification et configuration du modèle
Avant d’ajuster le modèle, nous devons définir les fonctions exposition-réponse et décalage-réponse basées sur les splines à l’aide du package {dlnm}.
Pour notre exemple, nous utiliserons des spécifications courantes dans la littérature dans les études température-mortalité :
-
-
Exposition-réponse : spline naturelle à trois nœuds placée aux 10e, 75e et 90e centiles de la température moyenne quotidienne
-
Réponse au décalage : spline naturelle avec trois nœuds équidistants sur l’échelle logarithmique jusqu’à un décalage maximum de 21 jours
-
# Exposure-response and lag-response spline parameters dlnm_var <- list( var_prc = c(10, 75, 90), var_fun = "ns", lag_fun = "ns", max_lag = 21, lagnk = 3 ) # Cross-basis parameters argvar <- list( fun = dlnm_var$var_fun, knots = quantile(london$tmean, dlnm_var$var_prc / 100, na.rm = TRUE), Bound = range(london$tmean, na.rm = TRUE) ) arglag <- list( fun = dlnm_var$lag_fun, knots = logknots(dlnm_var$max_lag, nk = dlnm_var$lagnk) ) # Create crossbasis cb <- crossbasis(london$tmean, lag = dlnm_var$max_lag, argvar, arglag)
Comme c’est généralement le cas dans ces scénarios, nous contrôlerons également le caractère saisonnier de la série chronologique de mortalité à l’aide d’une spline naturelle avec 8 degrés de liberté par an, qui contrôle de manière flexible les tendances à long terme et saisonnières de la mortalité :
seas <- ns(london$date, df = round(8 * length(london$date) / 365.25))
Enfin, il faut également définir les valeurs de température pour lesquelles des prédictions seront générées :
temp <- round(seq(min(london$tmean), max(london$tmean), by = 0.1), 1)
Ajuster le modèle
Ajuster le DLNM bayésien précédemment défini à l’aide de la fonction bdlnm(). Nous prélevons 1 000 échantillons de la distribution postérieure et définissons une graine pour la reproductibilité :
tictoc::tic() mod <- bdlnm( mort_75plus ~ cb + factor(dow) + seas, data = london, family = "poisson", sample.arg = list(n = 1000, seed = 5243) ) tictoc::toc()
8.33 sec elapsed
Intérieurement, bdlnm():
-
-
s’adapte au modèle en utilisant INLA
-
renvoie des échantillons postérieurs pour tous les paramètres
-
Température minimale de mortalité
Nous estimons la température minimale de mortalité (MMT), définie comme la température à laquelle le risque global de mortalité est minimisé. Cette valeur optimale sera ensuite utilisée pour centrer les risques relatifs estimés.
tictoc::tic() mmt <- optimal_exposure(mod, exp_at = temp) tictoc::toc()
7.3 sec elapsed
Le cadre bayésien, comparé à la perspective fréquentiste, fournit directement la distribution postérieure complète du MMT. Il est utile d’inspecter cette distribution pour évaluer s’il existe plusieurs valeurs d’exposition optimales candidates et pour vérifier que la médiane fournit une valeur de centrage raisonnable :
ggplot(as.data.frame(mmt$est), aes(x = mmt$est)) +
geom_histogram(
fill = "#A8C5DA",
bins = length(unique(mmt$est)),
alpha = 0.6,
color = "white"
) +
geom_density(
aes(y = after_stat(density) * length(mmt$est) / length(unique(mmt$est))),
color = "#2E5E7E",
linewidth = 1.2,
adjust = 2 # <-- key change: higher = smoother
) +
geom_vline(
xintercept = mmt$summary["0.5quant"],
color = "#2E5E7E",
linewidth = 1.1,
linetype = "dashed"
) +
scale_x_continuous(breaks = seq(min(mmt$est), max(mmt$est), by = 0.1)) +
labs(x = "Temperature (°C)", y = "Frequency") +
theme_minimal()
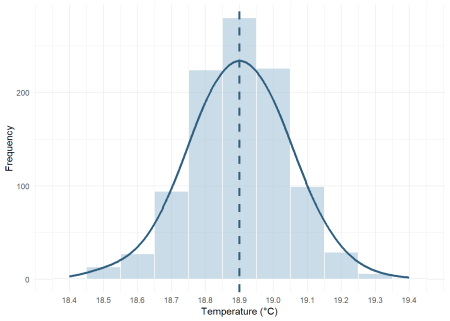
La distribution postérieure du MMT est concentrée autour de 18,9 ºC et est unimodale, de sorte que la médiane constitue une valeur de centrage stable pour les estimations du risque relatif.
La distribution postérieure du MMT peut également être visualisée directement à l’aide du package plot() méthode: plot(mmt).
Prédire les effets de l’exposition, du décalage et de la réponse
Nous prédisons l’association exposition-retard-réponse entre la température et la mortalité à partir du modèle ajusté à la grille de température fournie :
cen <- mmt$summary[["0.5quant"]] tictoc::tic() cpred <- bcrosspred(mod, exp_at = temp, cen = cen) tictoc::toc()
6.83 sec elapsed
Le centrage au MMT signifie que les risques relatifs (RR) sont interprétés par rapport à cette température optimale avec une mortalité minimale.
Plusieurs visualisations peuvent être produites à partir de ces prédictions. Bien que des visualisations plus simples puissent être créées à l’aide du package plot() méthode, nous utiliserons ici une méthode plus sophistiquée ggplot2 visualisations :
Surface d’exposition-retard-réponse 3D
Nous pouvons tracer l’association exposition-retard-réponse complète en utilisant une surface 3D :
matRRfit_median <- cpred$matRRfit.summary[,, "0.5quant"]
x <- rownames(matRRfit_median)
y <- colnames(matRRfit_median)
z <- t(matRRfit_median)
zmin <- min(z, na.rm = TRUE)
zmax <- max(z, na.rm = TRUE)
mid <- (1 - zmin) / (zmax - zmin)
plot_ly() |>
add_surface(
x = x,
y = y,
z = z,
surfacecolor = z,
cmin = zmin,
cmax = zmax,
colorscale = list(
c(0, "#00696e"),
c(mid * 0.5, "#80c8c8"),
c(mid, "#f5f0e8"),
c(mid + (1 - mid) * 0.5, "#c2714f"),
c(1, "#6b1c1c")
),
colorbar = list(title = "RR")
) |>
add_surface(
x = x,
y = y,
z = matrix(1, nrow = length(y), ncol = length(x)),
colorscale = list(c(0, "black"), c(1, "black")),
opacity = 0.4,
showscale = FALSE
) |>
layout(
title = "Exposure-Lag-Response Surface",
scene = list(
xaxis = list(title = "Temperature (°C)"),
yaxis = list(title = "Lag", tickvals = y, ticktext = gsub("lag", "", y)),
zaxis = list(title = "RR"),
camera = list(eye = list(x = 1.5, y = -1.8, z = 0.8))
)
)
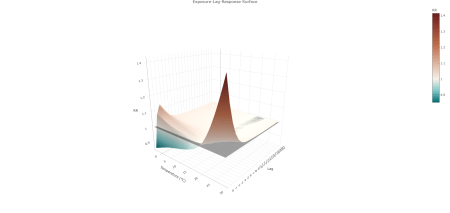
La surface révèle deux régions à risque distinctes. Les températures chaudes produisent un risque aigu et aigu, concentré dans les premiers décalages, culminant au décalage 0 et se dissipant rapidement après les premiers décalages. Les températures froides produisent une augmentation plus modeste et progressive des premiers décalages qui ne disparaît pas complètement avec des décalages plus longs. Les températures intermédiaires proches du MMT se situent à proximité du plan de référence RR = 1 sur tous les décalages.
La structure différentielle de décalage observée pour la mortalité liée à la chaleur et au froid est cohérente avec les mécanismes physiologiques connus. La mortalité liée à la chaleur a tendance à survenir rapidement après une exposition due à un stress physiologique aigu, tandis que la mortalité liée au froid se développe plus progressivement en raison d’effets cardiovasculaires et respiratoires retardés, entraînant un risque croissant sur des périodes de décalage plus longues.
Courbes de réponse en retard
On peut également visualiser des tranches de la surface précédente. Par exemple, la relation de retard de réponse pour différentes valeurs de température :
matRRfit <- cbind(
melt(cpred$matRRfit.summary[,, "0.5quant"], value.name = "RR"),
RR_lci = melt(
cpred$matRRfit.summary[,, "0.025quant"],
value.name = "RR_lci"
)$RR_lci,
RR_uci = melt(
cpred$matRRfit.summary[,, "0.975quant"],
value.name = "RR_uci"
)$RR_uci
) |>
rename(temperature = Var1, lag = Var2) |>
mutate(
lag = as.numeric(gsub("lag", "", lag))
)
temps <- cpred$exp_at
p <- ggplot() +
# Lag-responses curves colored by temperature
geom_line(
data = matRRfit,
aes(x = lag, y = RR, group = temperature, color = temperature),
alpha = 0.35,
linewidth = 0.35
) +
scale_color_gradientn(
colours = c(
"#2166ac",
"#4393c3",
"#92c5de",
"#d1e5f0",
"#f7f7f7",
"#fddbc7",
"#f4a582",
"#d6604d",
"#b2182b"
),
name = "Temperature"
) +
# Start a new color scale for highlighted curves
ggnewscale::new_scale_color() +
# RR = 1 reference
geom_hline(
yintercept = 1,
linetype = "dashed",
color = "grey30",
linewidth = 0.5
) +
scale_x_continuous(breaks = cpred$lag_at) +
scale_y_continuous(trans = "log10", breaks = pretty_breaks(6)) +
labs(
title = "Lag-response curves by temperature",
x = "Lag (days)",
y = "Relative Risk (RR)"
) +
theme_minimal() +
theme(legend.position = "top", panel.grid.minor.x = element_blank()) +
transition_states(
temperature,
transition_length = 1,
state_length = 0
) +
shadow_mark(past = TRUE, future = FALSE, alpha = 0.6)
animate(p, nframes = 300, fps = 15, end_pause = 100)
Les températures froides (en bleu) augmentent progressivement dans les délais initiaux, puis diminuent progressivement sans disparaître complètement dans les délais plus longs. Les températures chaudes (rouges) présentent un schéma différent : un risque plus élevé immédiatement après le décalage 0, qui diminue rapidement et se dissipe en grande partie après les premiers décalages :

Courbes exposition-réponses
Nous pouvons également tracer les courbes exposition-réponses par décalage et la courbe cumulée globale sur toute la période de décalage :
allRRfit <- data.frame(
temperature = as.numeric(rownames(cpred$allRRfit.summary)),
lag = "overall",
RR = cpred$allRRfit.summary[, "0.5quant"],
RR_lci = cpred$allRRfit.summary[, "0.025quant"],
RR_uci = cpred$allRRfit.summary[, "0.975quant"]
)
RRfit <- rbind(matRRfit, allRRfit)
# Split data
RRfit_lags <- RRfit |>
filter(!lag %in% c("overall")) |>
mutate(lag = as.numeric(lag))
RRfit_overall <- RRfit |>
filter(lag %in% c("overall"))
temps <- cpred$exp_at
t_cold <- temps[which.min(abs(temps - quantile(temps, 0.01)))]
t_hot <- temps[which.min(abs(temps - quantile(temps, 0.99)))]
# Top plot: exposure-response curves for each lag and overall
p_main <- ggplot() +
# Background: all lags, fading from vivid (small) to pale (large)
geom_line(
data = RRfit_lags,
aes(x = temperature, y = RR, group = lag, color = lag),
linewidth = 0.8
) +
scale_color_gradientn(
colours = c(
"black",
"#2b1d2f",
"#4a2f5e",
"#6a4c93",
"#8b6bb8",
"#b39cdb",
"#d8c9f1",
"#f3eef5"
),
values = scales::rescale(c(0, 0.5, 1, 2, 3, 4, 5, 10, 20))
) +
new_scale_color() +
new_scale_fill() +
# Credible intervals
geom_ribbon(
data = RRfit_overall,
aes(
x = temperature,
ymin = RR_lci,
ymax = RR_uci,
fill = "1"
),
alpha = 0.2
) +
# Highlighted curves
geom_line(
data = RRfit_overall,
aes(x = temperature, y = RR, color = "1"),
linewidth = 1.2
) +
geom_hline(
yintercept = 1,
linetype = "dashed"
) +
scale_color_manual(values = "#a6761d", labels = "Overall (CrI95%)") +
scale_fill_manual(values = "#a6761d", labels = "Overall (CrI95%)") +
scale_y_continuous(
transform = "log10",
breaks = sort(c(0.8, pretty_breaks(5)(c(0.8, 4))))
) +
labs(
x = NULL,
y = "Relative Risk (RR)",
color = NULL,
fill = NULL
) +
theme_minimal() +
theme(
legend.position = "top",
axis.text.x = element_blank(),
plot.margin = margin(8, 8, 0, 8)
)
# Bottom plot: histogram with percentile lines
p_hist <- ggplot(london, aes(x = tmean)) +
geom_histogram(
aes(y = after_stat(density), fill = after_stat(x)),
binwidth = 0.5,
color = "black",
linewidth = 0.2
) +
geom_vline(
xintercept = t_cold,
linetype = "dashed",
color = "#053061",
linewidth = 0.6
) +
geom_vline(
xintercept = t_hot,
linetype = "dashed",
color = "#67001f",
linewidth = 0.6
) +
geom_vline(
xintercept = cen,
linetype = "dashed",
color = "grey20",
linewidth = 0.6
) +
annotate(
"text",
x = t_cold,
y = Inf,
label = "1st pct",
vjust = 1.4,
hjust = 1.1,
size = 3.2,
color = "#053061"
) +
annotate(
"text",
x = t_hot,
y = Inf,
label = "99th pct",
vjust = 1.4,
hjust = -0.1,
size = 3.2,
color = "#67001f"
) +
annotate(
"text",
x = cen,
y = Inf,
label = "MMT",
vjust = 1.4,
hjust = -0.1,
size = 3.2,
color = "grey20"
) +
scale_x_continuous(limits = range(cpred$exp_at)) +
scale_fill_gradientn(
colours = c(
"#053061",
"#2166ac",
"#4393c3",
"#92c5de",
"#d1e5f0",
"#f7f7f7",
"#fddbc7",
"#f4a582",
"#d6604d",
"#b2182b",
"#67001f"
),
name = "Temperature"
) +
labs(x = "Temperature (°C)", y = "Density") +
theme_minimal() +
theme(
plot.margin = margin(20, 8, 8, 8),
legend.position = "bottom"
)
# Combine them:
p_main / p_hist + plot_layout(heights = c(3, 1))

La courbe cumulée globale (moutarde) est clairement asymétrique : le risque augmente des deux côtés du MMT, mais la hausse est beaucoup plus forte pour les températures chaudes que pour les températures froides. La courbe de décalage 0 (noire), qui reflète l’effet immédiat, se comporte différemment pour le froid que pour la chaleur : elle est inférieure à 1 aux températures froides (reflétant la nature différée des effets du froid) et augmente de manière approximativement linéaire pour la chaleur. L’histogramme confirme que la plupart des journées à Londres se situent entre 5°C et 20°C, de sorte que les températures extrêmes, malgré leurs risques individuels élevés, sont des événements relativement rares.
Risque attribuable
Nous pouvons également calculer les nombres et fractions attribuables à partir d’un B-DLNM, ce qui permet de quantifier l’impact de toutes les expositions observées sur la mortalité des plus de 75 ans. Nous calculons le nombre d’événements de mortalité attribuables aux expositions à la température (nombre attribuable) et la fraction de tous les événements de mortalité qu’il constitue (fraction attribuable).
Deux perspectives différentes peuvent être utilisées :
-
-
En arrière (
dir = "back") : quelles sont les causes des décès d’aujourd’hui qui s’expliquent par les expositions thermiques passées ? -
Avant (
dir = "forw") : quels décès futurs l’exposition à la température actuelle entraînera-t-elle ?
-
Utilisons la perspective prospective, plus couramment utilisée :
tictoc::tic() attr_forw <- attributable( mod, london, name_date = "date", name_exposure = "tmean", name_cases = "mort_75plus", cen = cen, dir = "forw" ) tictoc::toc()
110.12 sec elapsed
Evolution de la fraction attribuable
Nous pouvons tracer la série chronologique des fractions quotidiennes attribuables (AF) :
col_af <- "black"
temp_colours <- c(
"#053061",
"#2166ac",
"#4393c3",
"#92c5de",
"#d1e5f0",
"#f7f7f7",
"#fddbc7",
"#f4a582",
"#d6604d",
"#b2182b",
"#67001f"
)
af_med <- attr_forw$af.summary[, "0.5quant"]
# Pre-compute range once
af_min <- min(af_med, na.rm = TRUE) - 0.01
af_max <- max(af_med, na.rm = TRUE) + 0.01
df <- data.frame(
date = london$date,
x = yday(london$date),
year = year(london$date),
tmean = london$tmean,
af = af_med
)
ggplot(df, aes(x = x)) +
# Full-height temperature background per day
geom_rect(
aes(
xmin = x - 0.5,
xmax = x + 0.5,
ymin = af_min,
ymax = af_max,
fill = tmean
)
) +
scale_fill_gradientn(
colours = temp_colours,
name = "Temperature (°C)"
) +
# AF line on top
geom_line(
aes(y = af),
color = col_af,
linewidth = 0.7
) +
scale_y_continuous(
name = "Attributable Fraction (AF)",
breaks = seq(0, 1, by = 0.1),
limits = c(af_min, af_max),
expand = c(0, 0)
) +
scale_x_continuous(
breaks = yday(as.Date(paste0(
"2000-",
c("01", "03", "05", "07", "09", "11"),
"-01"
))),
labels = c("Jan", "Mar", "May", "Jul", "Sep", "Nov"),
expand = c(0, 0)
) +
facet_wrap(~year, ncol = 3, axes = "all_x") +
labs(x = NULL) +
theme_minimal(base_size = 11) +
theme(
panel.spacing.x = unit(0, "pt"),
strip.text = element_text(face = "bold", size = 10),
legend.position = "top",
legend.key.width = unit(2.5, "cm")
)
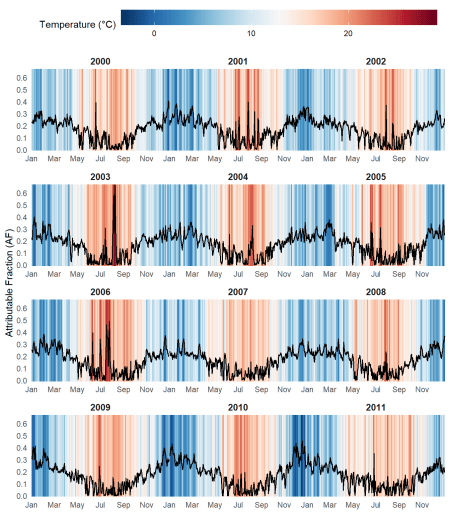
De brusques pics de FA dépassant 60 % sont visibles au cours des étés 2003 et 2006, coïncidant avec les principales vagues de chaleur européennes. En général, les épisodes d’été produisent des pics de FA plus élevés et plus abrupts, tandis que les journées froides d’hiver sont associées à des élévations plus soutenues dans le temps, bien que d’ampleur moins prononcée.
Charge totale imputable
En additionnant l’ensemble de la période d’étude, le tableau quantifie le fardeau total de la mortalité attribuable aux expositions à des températures non optimales dans la population de 75 ans et plus :
rbind( "Attributable fraction" = attr_forw$aftotal.summary, "Attributable number" = attr_forw$antotal.summary ) |> as.data.frame() |> round(3) |> gt(rownames_to_stub = TRUE)
| signifier | SD | 0.025quant | 0.5quant | 0,975quant | mode | |
|---|---|---|---|---|---|---|
| Fraction attribuable | 0,174 | 0,018 | 0,139 | 0,175 | 0,207 | 0,176 |
| Numéro attribuable | 68857.597 | 7131.526 | 55071.066 | 69178.391 | 81995.459 | 69842.155 |
Sur l’ensemble de la période 2000-2012, environ 17,5% (CrI à 95 % : 13,9 % à 20,7 %) de tous les décès dans la population de Londres de 75 ans et plus étaient imputables à des températures non optimales, ce qui correspond à environ 69 178 décès (CrI à 95 % : 55 071 à 81 996).
Conclusions
Le package {bdlnm} fournit une implémentation puissante et accessible des modèles non linéaires bayésiens à décalage distribué dans R. En combinant la flexibilité des DLNM avec l’inférence bayésienne complète via INLA, il permet aux chercheurs de mieux quantifier l’incertitude et d’adapter des relations complexes exposition-retard-réponse. Cela en fait un outil précieux pour étudier les impacts sur la santé du changement climatique et d’autres risques environnementaux dans des contextes de plus en plus riches en données.
Ce cadre ne se limite pas à l’épidémiologie environnementale. En fait, il peut être appliqué à tout contexte impliquant des expositions variables dans le temps et des effets différés (par exemple, des chocs de marché peuvent affecter les prix des actifs sur plusieurs jours), ce qui en fait un outil puissant et général pour l’analyse de séries chronologiques.
Le développement est en cours. Les fonctionnalités à venir incluent :
-
- Analyses multi-sites: regrouper les courbes exposition-retard-réponse de différentes villes ou régions au sein d’un seul modèle
- B-DLNM spatiaux (SB-DLNM): modéliser explicitement l’hétérogénéité spatiale dans les courbes exposition-retard-réponse de différentes régions
Le package est sur CRAN. Les rapports de bogues et les contributions sont les bienvenus via GitHub.
Références
-
-
Gasparrini A. (2011). Modèles linéaires et non linéaires à décalage distribué dans R : le package dlnm. Journal des logiciels statistiques43(8), 1-20. est ce que je:10.18637/jss.v043.i08.
-
Quijal-Zamorano M., Martinez-Beneito MA, Ballester J., Marí-Dell’Olmo M. (2024). Modèles non linéaires à décalage distribué spatial bayésien (SB-DLNM) pour la modélisation épidémiologique exposition-retard-réponse sur de petites zones. Journal international d’épidémiologie53(3), colorant061. est ce que je:10.1093/ije/dyae061.
-
Rue H., Martino S., Chopin N. (2009). Inférence bayésienne approximative pour les modèles gaussiens latents en utilisant des approximations de Laplace imbriquées intégrées. Journal de la Royal Statistical Society : série B71(2), 319-392. est ce que je:10.1111/j.1467-9868.2008.00700.x.
-
Gasparrini A., Leone M. (2014). Risque attribuable aux modèles de décalage distribué. Méthodologie de recherche médicale BMC14, 55. est ce que je:10.1186/1471-2288-14-55.
-
Nouveau package R {bdlnm} publié sur CRAN : modèles bayésiens à décalage distribué non linéaires dans R via INLA a été publié pour la première fois le 10 avril 2026 à 17h14.
Offres R-bloggers.com mises à jour quotidiennes par e-mail sur l’actualité de R et des tutoriels sur l’apprentissage de R et bien d’autres sujets. Cliquez ici si vous souhaitez publier ou trouver un emploi en R/data-science.
Vous souhaitez partager votre contenu sur R-bloggers ? cliquez ici si vous avez un blog, ou ici si vous n’en avez pas.
Continuer la lecture: Nouveau package R {bdlnm} publié sur CRAN : modèles non linéaires bayésiens à décalage distribué dans R via INLA
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.