Vous souhaitez partager votre contenu sur R-bloggers ? cliquez ici si vous avez un blog, ou ici si vous n’en avez pas.
Sur les marchés financiers, faire la distinction entre mouvements axés sur l’information et chocs liés à la liquidité est critique. L’étude de référence nous avons basé notre travail sur l’importance de analyse de la queue: comparer les distributions gaussiennes (à queue fine) et Student‑t (à queue large) pour comprendre si les changements de prix sont plus susceptibles de refléter de véritables informations ou des déséquilibres temporaires de liquidité.
Les rendements financiers se comportent rarement aussi bien que le suppose la distribution gaussienne (normale). En théorie, les mouvements de prix extrêmes devraient être extrêmement rares dans un modèle gaussien à queue fine. Pourtant, dans la pratique, les marchés affichent fréquemment grosses queues: grands sauts, crashs et pics qui se produisent beaucoup plus souvent que ne le prédit la théorie gaussienne.
Cet écart motive analyse de la queue—une approche statistique qui compare dans quelle mesure différentes distributions expliquent les données observées. Deux candidats courants sont :
- Distribution gaussienne (queues fines) : Si les rendements correspondent mieux à ce modèle, les mouvements extrêmes sont interprétés comme axé sur l’information. En d’autres termes, de nouvelles informations sont entrées sur le marché et les changements de prix sont plus susceptibles de refléter de véritables changements dans les fondamentaux ou les attentes.
- Distribution Student‑t (grosses queues) : Si les rendements correspondent mieux à ce modèle, les mouvements extrêmes sont pris en compte axé sur la liquidité. Ces chocs résultent souvent de déséquilibres temporaires dans les flux de commandes ou de contraintes de liquidité, et les prix ont tendance à s’inverser une fois le déséquilibre atténué.
En comparant les log-vraisemblances des ajustements gaussiens et Student-t, nous pouvons classer le comportement du marché dans ces deux régimes. Cette classification n’est pas seulement académique : elle aide les traders, les gestionnaires de risques et les analystes à faire la distinction entre poursuite de la tendance (axés sur l’information) et retour à la moyenne (piloté par la liquidité).
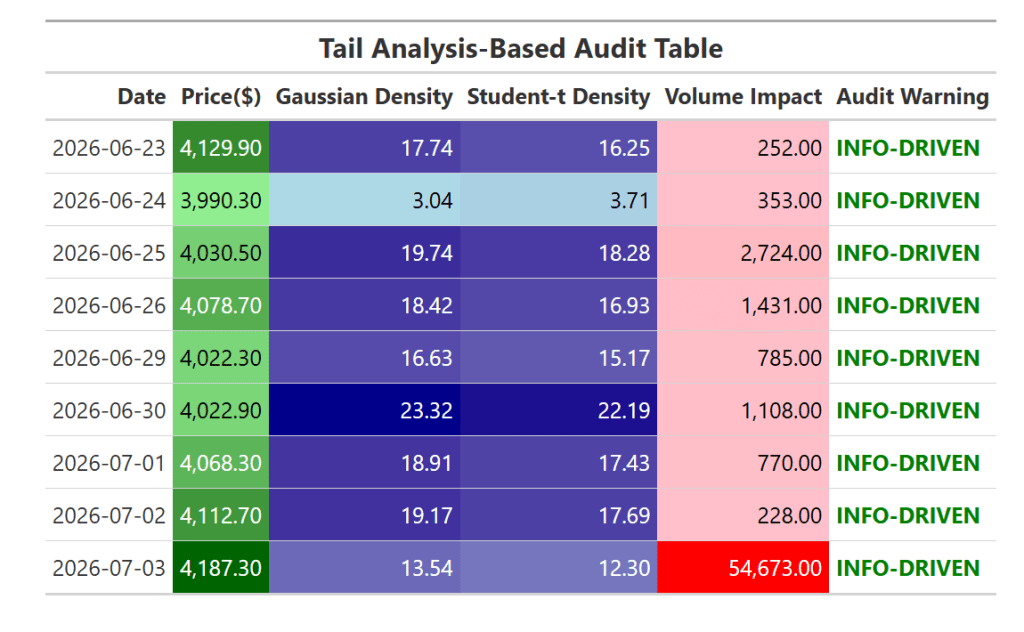
Dans notre workflow, nous appliquons cette analyse de queue à contrats à terme sur l’or (GC=F) au cours des 15 derniers jours de bourse. Nous calculons les rendements logarithmiques, ajustons les deux distributions et comparons leurs probabilités. Nous enrichissons ensuite l’analyse avec un mesure de l’impact sur le volumequi met en évidence si une activité commerciale anormale amplifie les changements de prix. Enfin, nous présentons les résultats dans un tableau d’audit codé par couleur qui rend le comportement de la queue visuellement interprétable.
Pourquoi ces packages R ?
- marée inverse: Fournit une grammaire cohérente pour la manipulation des données (
mutate,drop_na,select). Il garantit la reproductibilité et la lisibilité lors de la transformation des données brutes du marché en rendements logarithmiques et en mesures dérivées. - tidyquant: Fait le pont entre les sources de données financières et l’écosystème Tidyverse. Nous l’utilisons pour récupérer des données sur les contrats à terme sur l’or (
GC=F) directement depuis Yahoo Finance, ce qui rend le flux de travail autonome et facile à étendre à d’autres tickers. - MASSE: Propose des outils statistiques pour l’ajustement de la distribution. Nous comptons sur
fitdistr()pour estimer les paramètres des distributions gaussienne et Student‑t, permettant une comparaison directe des log‑vraisemblances. - GT: Fournit un rendu de table professionnel. Il nous permet de formater des nombres, d’appliquer des échelles de couleurs et de mettre en évidence les avertissements d’audit, transformant ainsi la sortie statistique brute en un tableau d’audit visuellement interprétable.
library(tidyverse) # Load tidyverse for data manipulation
library(tidyquant) # Load tidyquant for financial data retrieval
library(MASS) # Load MASS for distribution fitting
library(gt) # Load gt for table rendering
ticker <- "GC=F" # Define the ticker symbol (Gold Futures)
horizon <- 15 # Set horizon to last 15 days
# Fetch market data for the chosen ticker and horizon
market_data <- tq_get(ticker, from = Sys.Date() - horizon, to = Sys.Date())
# Compute log returns and drop missing values
market_tbl <- market_data %>%
mutate(returns = log(adjusted) - log(lag(adjusted))) %>%
drop_na()
# Gaussian fit
fit_gauss <- fitdistr(market_tbl$returns, densfun = "normal")
# Student-t fit
fit_t <- fitdistr(
market_tbl$returns,
densfun = function(x, df, mean, sd) dt((x - mean)/sd, df)/sd,
start = list(df = 5, mean = mean(market_tbl$returns), sd = sd(market_tbl$returns))
)
# Compare log-likelihoods
ll_gauss <- fit_gauss$loglik
ll_t <- fit_t$loglik
signal <- if (ll_gauss > ll_t) "INFO-DRIVEN" else "LIQUIDITY-DRIVEN"
# Build audit table
audit_tbl <- market_tbl %>%
mutate(
Gaussian_Density = dnorm(returns, mean = mean(returns), sd = sd(returns)),
StudentT_Density = dt((returns - mean(returns))/sd(returns), df = 5)/sd(returns),
Volume_Impact = abs(volume)^ifelse(signal == "INFO-DRIVEN", 1.0, 0.6),
Audit_Warning = signal
) %>%
dplyr::select(Date = date,
Price = adjusted,
Gaussian_Density,
StudentT_Density,
Volume_Impact,
Audit_Warning)
#GT Table
audit_gt <- audit_tbl %>%
gt() %>%
tab_header(title = md("**Tail Analysis-Based Audit Table**")) %>%
cols_label(
Date = md("**Date**"),
Price = md("**Price**"),
Gaussian_Density = md("**Gaussian Density**"),
StudentT_Density = md("**Student-t Density**"),
Volume_Impact = md("**Volume Impact**"),
Audit_Warning = md("**Audit Warning**")
) %>%
fmt_number(columns = c(Price, Gaussian_Density, StudentT_Density, Volume_Impact),
decimals = 2, use_seps = TRUE) %>%
data_color(
columns = c(Price),
colors = scales::col_numeric(
palette = c("lightgreen","darkgreen"),
domain = range(audit_tbl$Price, na.rm = TRUE)
)
) %>%
data_color(
columns = c(Gaussian_Density, StudentT_Density),
colors = scales::col_numeric(
palette = c("lightblue","darkblue"),
domain = range(c(audit_tbl$Gaussian_Density,
audit_tbl$StudentT_Density), na.rm = TRUE)
)
) %>%
data_color(
columns = c(Volume_Impact),
colors = scales::col_numeric(
palette = c("pink","red"),
domain = c(min(audit_tbl$Volume_Impact, na.rm = TRUE),
max(audit_tbl$Volume_Impact, na.rm = TRUE))
)
) %>%
text_transform(
locations = cells_body(columns = vars(Audit_Warning)),
fn = function(x) {
ifelse(x == "INFO-DRIVEN",
"<span style='color:green;font-weight:bold;'>INFO-DRIVEN</span>",
"<span style='color:red;font-weight:bold;'>LIQUIDITY-DRIVEN</span>")
}
)
audit_gt

En rapport
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.
