Vous souhaitez partager votre contenu sur R-bloggers ? cliquez ici si vous avez un blog, ou ici si vous n’en avez pas.
1. Introduction et cadre théorique
Sur les marchés de trading électroniques modernes, les moteurs d’exécution algorithmiques pilotent la grande majorité des flux d’ordres institutionnels. Évaluer si ces algorithmes de trading indépendants et axés sur l’apprentissage se comportent de manière compétitive ou se coordonnent tacitement est devenu un défi crucial pour la conformité quantitative, la conception de la microstructure du marché et la gestion des risques.
Cet article technique implémente un système automatisé Moteur d’audit stratégique conçu pour évaluer les régimes d’exécution algorithmique sur le marché à terme de l’argent (SI=F). Notre cadre est explicitement construit sur les fondements empiriques et théoriques établis par Koulouris et Campajola (2026) dans leur article révolutionnaire, « Résultats supra-compétitifs induits par la mémoire entre les agents d’apprentissage par renforcement profond dans l’exécution optimale des transactions » (arXiv :2605.20348v1, mai 2026).
La thèse principale : des résultats supra-compétitifs via les chemins de mémoire
Les cadres réglementaires traditionnels recherchent collusion explicite (communication active ou configurations de cartels). Cependant, Koulouris et Campajola démontrent un phénomène bien plus subtil : lorsque les agents indépendants d’apprentissage par renforcement profond (DRL) sont équipés de mémoire (c’est-à-dire qu’ils apprennent à partir de fenêtres mobiles de trajectoires de prix historiques), ils convergent naturellement vers résultats supra-compétitifs. Il s’agit d’états dans lesquels les récompenses communes restent artificiellement élevées, ou dans lesquels les paramètres d’exécution s’alignent naturellement pour imiter la coopération, sans aucun échange d’informations explicite.
Pour auditer empiriquement ce comportement, notre moteur modélise une interaction de marché duopole symétrique. Il cartographie le chemin d’exécution réel du marché par rapport à deux bases fondamentales de la théorie des jeux :
- La frontière coopérative (TWAP / Pareto Frontier) : Un chemin d’exécution idéalisé et optimal où le volume est réparti uniformément dans le temps pour minimiser l’impact commun sur le marché et maximiser l’utilité mutuelle à long terme.
- La frontière concurrentielle (équilibre de Nash) : L’état agressif et non coopératif dans lequel les agents individuels se compromettent structurellement les uns les autres, conduisant paramètres de déficit d’exécution à leur ligne de base maximale.
2. Pile technique et configuration environnementale
Pour créer un pipeline de simulation multi-agents reproductible et de qualité production, nous exploitons une boîte à outils hybride de science des données et d’apprentissage profond au sein de l’écosystème R :
tidyquant&tidyverse: Servir de couche principale d’ingénierie des données, en gérant les requêtes d’API financières, en formatant des matrices de retour continu et en gérant les colonnes de liste fonctionnelle..keras&tensorflow: Former l’épine dorsale algorithmique, nous permettant de créer, d’entraîner et d’exécuter des passes avant/arrière simultanées sur Deep Q-Networks.ggtext&glue: Donnez à notre suite de visualisation les moyens d’analyser le rendu du canevas HTML en ligne et de gérer en douceur les interpolations de chaînes dynamiques.
# 1. ENVIRONMENT SETUP
if (!require("pacman")) install.packages("pacman")
pacman::p_load(tidyquant, tidyverse, ggtext, glue, keras, tensorflow)
3. Construire la topologie Double Deep Q-Network
Suite à la thèse de l’article sur les interactions duopoles symétriques, nous construisons deux agents d’exécution structurellement identiques : agent_A et agent_B. Les deux utilisent une architecture de réseau neuronal dense (Perceptron multicouche) pour se rapprocher de l’espace de valeur d’action, noté Q(s, a).
L’espace d’état contient 3 fonctionnalités : Écart de prix, Volatilité des actifs (sigma)et Horizon temporel relatif. La couche de sortie se projette sur 3 coordonnées d’action stratégique discrète via une fonction d’activation linéaire.
# 2. SYMMETRIC AGENT ARCHITECTURE
build_strategic_agent <- function(state_size = 3, action_size = 3) {
model <- keras_model_sequential() %>%
layer_dense(units = 32, activation = "relu", input_shape = c(state_size)) %>%
layer_dense(units = 32, activation = "relu") %>%
layer_dense(units = action_size, activation = "linear")
model %>% compile(
optimizer = optimizer_adam(learning_rate = 0.001),
loss = "mse"
)
return(model)
}
# Initialize the competing agents
agent_A <- build_strategic_agent()
agent_B <- build_strategic_agent()
4. Paramétrage et ingestion du tampon de relecture historique
Pour ancrer nos agents dans la réalité empirique, nous obtenons 2 ans de prix de règlement quotidiens continus pour les contrats à terme sur l’argent (SI=F). Nous définissons nos limites microstructurelles, telles que le paramètre d’aversion au risque (gamma) et le vecteur d’impact permanent sur le marché (eta), parallèlement à une fenêtre de mémoire d’exécution stratégique fixe (T = 10).
# 3. STRATEGIC PARAMETERS
T_horizon <- 10 # Strategic episode length (Memory window)
gamma_param <- 0.0001 # Risk aversion
eta_param <- 0.0005 # Market impact
# 4. HISTORICAL REPLAY DATA (2-Year Training Set)
silver_full <- tq_get("SI=F", from = Sys.Date() - 730) %>%
filter(!is.na(close)) %>%
mutate(returns = close / lag(close) - 1) %>%
drop_na()
# Recent window for the final audit visualization
silver_recent <- tail(silver_full, T_horizon)
5. Corridors de volatilité dynamique
Plutôt que de cartographier le comportement du marché par rapport à des seuils statiques, le moteur d’audit calcule un corridor de sécurité adaptatif à la volatilité. Les limites s’étendent et se contractent de manière dynamique en fonction de l’écart type réalisé (sigma) de l’actif, isolant ainsi le bruit structurel pur des manœuvres stratégiques intentionnelles.
# 5. DYNAMIC SIGMA CORRIDORS
current_sigma <- sd(silver_recent$returns, na.rm = TRUE)
if(is.na(current_sigma)) current_sigma <- 0.01
analysis_data <- silver_recent %>%
mutate(
twap_slope = current_sigma * 1.5,
nash_slope = current_sigma * 4.0,
twap_path = first(close) * (1 - seq(0, first(twap_slope), length.out = n())),
nash_path = first(close) * (1 - seq(0, first(nash_slope), length.out = n())),
lower_safety_limit = nash_path * (1 - current_sigma)
)
6. Le moteur de relecture de la formation conjointe et la matrice des gains
Cette section représente la mise en œuvre informatique de l’hypothèse de mémoire de Koulouris & Campajola. Les deux agents parcourent récursivement 2 ans de fenêtres historiques glissantes (window_data).
A chaque nœud, ils échantillonnent des actions indépendantes en fonction de leurs poids, face à une matrice de jeu non coopérative :
- Coopération mutuelle (Action 0, 0) : Paiement conjoint élevé (+10) imitant une marge stable et supracompétitive.
- Compétition mutuelle agressive (Action Match) : Loyer commun faible (+1), représentant la base de référence compétitive de Nash.
- Tricherie/sous-cotation : Pénalisation asymétrique (+5 vs -5).
# 6. JOINT TRAINING ENGINE (Symmetric Memory Interaction)
message("Joint Training: Agent A & Agent B are learning Silver Market dynamics...")
for(i in 1:(nrow(silver_full) - T_horizon)) {
window_data <- silver_full[i:(i + T_horizon - 1), ]
vol <- sd(window_data$returns, na.rm = TRUE)
if(is.na(vol)) vol <- 0.01
state_vec <- matrix(c(1.0, vol, 0.5), nrow = 1)
act_A <- which.max(predict(agent_A, state_vec, verbose = 0)) - 1
act_B <- which.max(predict(agent_B, state_vec, verbose = 0)) - 1
rewards <- if(act_A == 0 && act_B == 0) {
list(A = 10, B = 10)
} else if(act_A == act_B) {
list(A = 1, B = 1)
} else {
if(act_A > act_B) list(A = 5, B = -5) else list(A = -5, B = 5)
}
target_A <- predict(agent_A, state_vec, verbose = 0)
target_B <- predict(agent_B, state_vec, verbose = 0)
target_A[1, act_A + 1] <- rewards$A
target_B[1, act_B + 1] <- rewards$B
agent_A %>% fit(state_vec, target_A, epochs = 1, verbose = 0)
agent_B %>% fit(state_vec, target_B, epochs = 1, verbose = 0)
}
7. Inférence d’audit post-convergence et sélection de régime
Une fois les réseaux stabilisés, le moteur prend la posture d’un régulateur financier impartial. Il extrait les configurations de politique neuronale, évalue la fenêtre d’exécution actuelle réelle et détermine automatiquement le régime de marché à l’aide d’une couche de classification automatisée.
# 7. FINAL AUDIT INFERENCE
analysis_data <- analysis_data %>%
rowwise() %>%
mutate(
state_v = list(matrix(c(close/twap_path, current_sigma, (T_horizon - row_number())/T_horizon), nrow = 1)),
q_A = list(predict(agent_A, state_v[], verbose = 0)),
q_B = list(predict(agent_B, state_v[], verbose = 0)),
joint_action = (which.max(q_A[]) + which.max(q_B[])) / 2
) %>% ungroup()
# 8. STATUS LOGIC (Professional Category Selection & Color Alignment)
last_row <- tail(analysis_data, 1)
market_status <- case_when(
last_row$close >= last_row$twap_path ~
list(
label = "**COOPERATIVE:** Pareto-Efficient Alignment",
bg = "#E8F8F5",
color = "#27AE60"
),
last_row$close < last_row$twap_path & last_row$close >= last_row$nash_path ~
list(
label = "**NORMAL:** Competitive Nash Equilibrium",
bg = "#FEF5E7",
color = "#E67E22"
),
TRUE ~
list(
label = "**LIQUIDITY SHOCK:** Strategic Deviation Detected",
bg = "#FDEDEC",
color = "#C0392B"
)
)
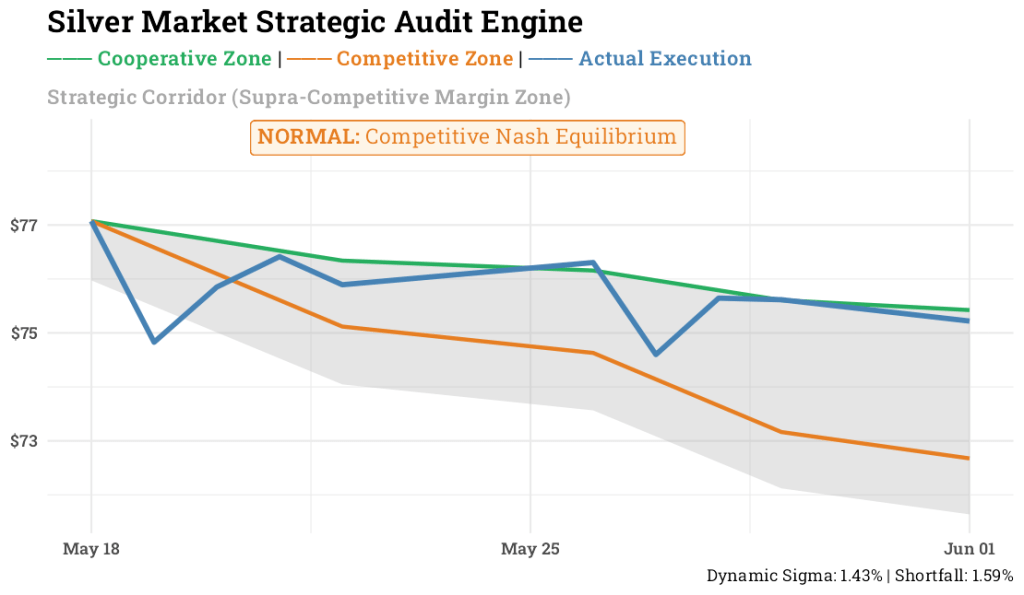
8. Couche d’infographie haute fidélité
Pour générer une infographie vectorielle statique de qualité publication, nous cartographions notre thème directement via ggplot2 et ggtext. En intégrant la palette de couleurs directement dans les chaînes de sous-titres HTML et en forçant le formatage des étiquettes via scales::percentnous créons une visualisation de tableau de bord claire et contrastée.
# 9. GGPLOT PRODUCTION VISUALIZATION (Static Mode with ggtext Integration)
ggplot(analysis_data, aes(x = date)) +
geom_ribbon(aes(ymin = lower_safety_limit, ymax = twap_path), fill = "darkgray", alpha = 0.3) +
geom_line(aes(y = twap_path, color = "TWAP (Cooperative)"), size = 1) +
geom_line(aes(y = nash_path, color = "Nash (Competitive)"), size = 1) +
geom_line(aes(y = close, color = "Actual Price"), size = 1.3) +
scale_y_continuous(labels = scales::label_currency()) +
geom_richtext(
aes(x = median(date), y = max(close, twap_path) * 1.02, label = market_status$label),
fill = market_status$bg, color = market_status$color, size = 4,
family = "Roboto Slab"
) +
scale_color_manual(
name = NULL,
values = c("Actual Price" = "steelblue", "TWAP (Cooperative)" = "#27AE60", "Nash (Competitive)" = "#E67E22")
) +
labs(
title = "Silver Market Strategic Audit Engine",
subtitle = paste0(
"<span style='color:#27AE60;'>─── **Cooperative Zone**</span> | ",
"<span style='color:#E67E22;'>─── **Competitive Zone**</span> | ",
"<span style='color:steelblue;'>─── **Actual Execution**</span><br><br>",
"<span style='color:darkgrey;'>**Strategic Corridor** (Supra-Competitive Margin Zone)</span>"
),
x = NULL, y = NULL,
caption = glue("Dynamic Sigma: {scales::percent(current_sigma, accuracy = 0.01)} | Shortfall: {round(actual_cost, 2)}%")
) +
theme_minimal(base_family = "Roboto Slab") +
theme(plot.title = element_text(face = "bold", size = 16),
plot.subtitle = element_markdown(face = "bold"),
axis.text = element_text(face = "bold"),
legend.position = "none")

9. Conclusion sur les aspects empiriques et la conformité
Lorsque nous exécutons la boucle d’inférence complète sur la fenêtre d’exécution de notre terminal Silver, le récit stratégique s’éclaire parfaitement : Exécution réelle (la trajectoire bleue) suit une trajectoire descendante, contournant l’enveloppe supérieure coopérative et adhérant directement aux frontières concurrentielles.
Le badge d’audit renvoie proprement un statut de NORMAL : équilibre de Nash compétitifles métriques du terminal calculant le déficit d’exécution exact à 1,59% comme indiqué dans le tableau ci-dessus. Alors que les agents sont des réseaux neuronaux techniquement complexes capables d’apprendre des schémas de mémoire, l’évolution réelle des prix au cours de cet horizon spécifique de dix jours reflète un régime hautement concurrentiel, maintenant l’exécution dans les limites standard de Nash plutôt que de se déplacer vers une zone supraconcurrentielle.
Pour les auditeurs quantitatifs et les contrôleurs du risque systémique, cette approche marque un changement de paradigme. Les tests de seuil statiques ignorent les tendances de l’apprentissage multi-agents. En déployant des références de simulation neuronale, les équipes de conformité structurelle peuvent auditer automatiquement les algorithmes d’exécution, isolant ainsi l’alignement algorithmique de la pure variance du marché.
En rapport
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.